
Mit Faszination habe ich letzte Woche beobachtet, mit wie viel Entsetzen die Medien und viele der CEO's der Amerikaner auf die Nachricht reagiert haben, dass ein neues und günstigeres Modell genau so gut sein soll wie das von OpenAI.
Zunächst einmal: vor ca. 4 Monaten hatte das Qwen Team, das zu $BABA (+1,33 %) gehört, die Qwen 2.5 Modellserie released. Diese reichten von 0.5b bis hin zu 72b. Das 72b Modell erreichte eine weitaus bessere Performance als jegliche bereits auf dem Markt existierenden Open Source LLMs, inklusive Meta Llama 3.3:
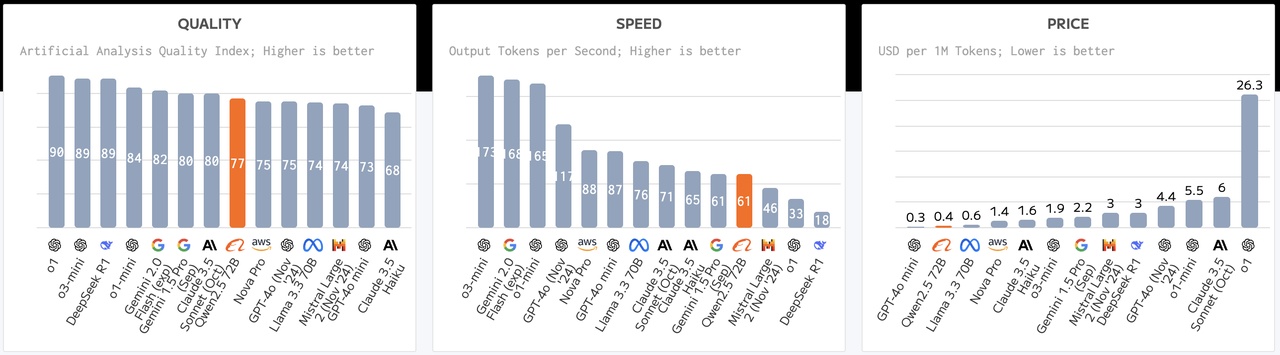
Wie man sieht ist die Performance nur bedingt schlechter, je nachdem welche Benchmark man nimmt, ist sie sogar besser als Modelle von Anthropic's Claude, OpenAI's GPT-4o und Google's Gemini. Wie viel Aufsehen hat das erregt: 0.
Zumindest in den Medien. Für uns Entwickler ist aber der ständige Fortschritt der open source Modelle ein Blessing, da wir die Modelle zum Beispiel im Falle von qwen2.5:72b quasi einmal komplett runterladen und auf privaten Servern zum laufen bringen, sodass sie abgeschnitten von jeglichen Daten lokal arbeiten. Das bedeutet keinerlei Daten können über eine API Anfrage wie zum Beispiel bei OpenAI's Modellen (eigentlich ein Witz dass sie OpenAI heißen) an den Provider OpenAI zurückfließen und sie diese Daten nicht zum Nachtrainieren ihrer Modelle nutzen können. Dies ist vor allem bei Applikationen mit kritischen Daten essenziell.
By the way wer gerne seinen eigene persönlcihen Assistenten auf seinem Rechner laufen lassen möchte, kann dies zum Beispiel mit der open-source Software Ollama tun. Falls ihr nicht wisst wie viel euer Laptop händeln kann, wenn ihr nicht gerade eine Grafikkarte mit 64GB RAM installiert habt, dann hier eine kurze Übersicht:
- <=3b Modelle ca. 5GB RAM (z.b. LLama 3.2 3b, qwen2.5:3b)
- 7/8/9b Modelle ca. 16GB RAM (z.b. qwen2.5:7b, llama3.1:8b)
- <=70b Modelle ca. 64GB RAM (aber ultra langsam auf CPU only, braucht dann nen Mac mit Apple Silicon oder so)
Also zusammengefasst: selbst mit 3 Jahre altem Windows Rechnern die 32GB RAM haben und nen Intel oder AMD Prozessor könnt ihr LLMs bei euch laufen lassen.
ollama link: https://ollama.com/
So zurück zum Topic: warum hat keiner etwas zum Qwen Erfolg gesagt?
Vielleicht einfach auch weil Qwen's Erfolg nicht mit größeren Tweaks in der Modellarchitektur zu tun hatte. Es ist nämlich so, dass das DeepSeek Team ein paar entscheidende Änderungen in der Modellarchitektur vorgenommen hat, vornehmlich 2 Stück:
Statt das Basismodell mit supervised Finetuning, also vereinfacht gesagt mit gelabeltem Datensatz (gute Antwort/schlechte Antwort) zu trainieren, haben sie es pur mit Reinforcement Learning trainiert (mathematisch eine Art Reward einprogrammiert, wenn gewünschte Trainingserfolge erzielt werden)
In dem Reinforcement Learning Ansatz haben sie ebenfalls entscheidende Änderungen vorgenommen und eine neue Technik (Group Relative Policy Optimization GRPO) etabliert, welche sehr vereinfacht den Feedback Prozess des positiven Lernens beschleunigt.
paper: https://arxiv.org/pdf/2501.12948
Jetzt zum wichtigsten Teil:
Warum DeepSeek einen Teil "weggelassen" hat und warum es für uns Investoren sehr gut sein kann
In einem ausführlichen Artikel hat semianalysis noch einmal aufgeführt, warum gewisse Zahlen nicht so Sinn machen.
TL;DR:
- $6M "training cost" ist irreführend – exkludiert Infrastruktur und operative Kosten ($1.3Mrd. server CapEx, $715Mio. operating costs)
- ~50,000+ GPUs (H100/H800/H20) über Umwege bekommen (H100 verbotene GPUS!)
- Sie könnten Inferenz auch einfach günstig anbieten, wie Google Gemini, (50% günstiger als GPT-4o) um Marktanteil zu gewinnen
- Ein Export Wurmloch ermöglichte anscheinend ein $1.3Mrd. Ausbau vor H20 Export Restriktionen
- DeepSeek R1 "reasoning" ist gut, aber Google Gemini's Flash 2.0 ist günstiger und genau so gut mindestens (aus beruflicher Erfahrung: die Gemini Modelle sind mittlerweile sehr gut geworden)
- in den operativen Kosten die nicht bekannt gemacht worden sind schätzungsweise die Gehälter für Toptalenten in Höhe von bis zu $1.3Mio USD (per capita)
source: https://semianalysis.com/2025/01/31/deepseek-debates/
ASML CEO sagt das dazu:
"In Fouquet's perspective, any reduction in cost is beneficial for ASML. Lower costs would allow artificial intelligence (AI) to be implemented in more applications. More applications, in turn, would necessitate more chips."
source: https://www.investing.com/news/stock-market-news/asml-ceo-optimistic-over-deepseek-93CH-3837637
Persönlich sehe ich es ähnlich, dass AI in Zukunft günstiger und besser wird, dafür müssen Chips ebenfalls besser sein und vor allem mehr Chips produziert werden. Ohne zu tief ins Detail zu gehen, war das eine gute Gelegenheit z.B. $ASML (+2,73 %) , $TSM (+0,89 %) , $NVDA (+3,82 %) und co. zu kaufen.








