Liebe Community! 🙏
Das Thema AI ist allgegenwärtig.
Viele rufen laut, dass es an der Börse mittlerweile eine Blase sei und den hohen Erwartungen kurz- und mittelfristig nicht standhalten könne.
Fest steht, dass LLMs wie ChatGPT oder Gemini aus dem Leben vieler nicht mehr wegzudenken sind.
Noch weit entfernt von „perfekt“, verströmt generative AI dennoch eine surreale Magie, die wir uns noch vor fünf Jahren nicht in unseren kühnsten Träumen hätten vorstellen können.
Große Unternehmen wie zuletzt Accenture entlassen massiv Personal im Zuge eines großen „AI-Restructuring“.
Es scheint klar zu werden, dass AI schon bald massive Verwerfungen in Wirtschaft und Gesellschaft verursachen wird.
Letzte Woche habe ich meine Vorbestellung von Eliezer Yudkowskys neuem Buch zum Thema „superintelligent AI“ erhalten und in zwei Tagen verschlungen.
Obwohl es in diesem Post nicht direkt um Börseninvestments geht, ist das Thema meiner Meinung nach wichtig genug, um euch zu interessieren.
Schnallt euch an für eine Runde existenzielle Angst am Montag 😎✨
__________________________
❓Worum geht's hier genau?
Yudkowsky, der Autor, ist Mitgründer des „Machine Intelligence Research Institute“ in Berkeley und hatte schon vor über 20 Jahren vor den existenziellen Risiken fortgeschrittener KI-Systeme gewarnt.
Der Titel „If Anyone Builds It, Everyone Dies“ seines neuesten Buchs klingt zunächst nach reißerischer Übertreibung …
Obwohl ich die Grundthese zu den Gefahren von AGI (Artificial General Intelligence) bereits im Vorfeld kannte, habe ich mir nicht allzu viel dabei gedacht.
Bei den Abermilliarden, die in den Sektor fließen, werden sich schlaue Köpfe doch sicherlich Gedanken zur Sicherheit (AI Alignment) machen … oder? 🤔
Um die Kernaussage des Buches vorwegzunehmen:
Yudkowsky und Co-Autor Nate Soares gehen so weit zu sagen, dass, wenn wir weiter an den Fähigkeiten künstlicher Intelligenz forschen und immer bessere Modelle trainieren, dies zweifellos zum sicheren Untergang der Menschheit führen wird.
__________________________
⬛Funktionsweise von LLMs und Blackbox-Realität:
Wir wissen erstaunlich wenig darüber, wie LLMs intern funktionieren.
„Mechanistic Interpretability“ forscht daran, aber ein allgemeines, skalierbares Verständnis fehlt.
Das liegt fundamental daran, dass LLMs nicht „programmiert“ werden, sondern analog zur biologischen Evolution „wachsen“.
Hier eine rudimentäre Erklärung der Funktionsweise, welche aber ausreicht um das Problem zu verdeutlichen:
Ein Transformer-Modell besteht aus Milliarden Parametern, deren Weights zunächst zufällig gesetzt sind.
Beim Training bekommt es Aufgaben in Form von Texten und versucht, das nächste Wort vorherzusagen.
Anhand des Fehlers zwischen Vorhersage und richtiger Antwort wird durch Gradient Descent berechnet, in welche Richtung und wie stark jedes Weight verändert werden muss, um das Ergebnis zu verbessern.
Dieser Vorgang wird über unvorstellbar viele Texte hinweg wiederholt, wobei die Weights sich immer weiter anpassen.
So „lernt“ der Transformer allmählich Sprachmuster, Bedeutung und Kontext, bis er kohärent schreiben kann.
__________________________
😶🌫️Unsichtbare Präferenzen:
Systeme, die über Gradient Descent wachsen, können Ziele lernen, die nicht unseren Intentionen entsprechen.
Sie optimieren ein Trainingsziel und lernen dabei interne Heuristiken bzw. „Werte“.
Aus dieser Lern-Dynamik entstehen instrumentelle Ziele (Ressourcen sichern, Abschaltung vermeiden), die mit menschlichen Zielen kollidieren können.
Das ist bei AI-Modellen bereits empirisch beobachtet worden und stützt die Angst vor versteckten Wünschen, die erst außerhalb des Trainings sichtbar werden.
Das „Alignment“ ist somit, Stand heute, unlösbar.
__________________________
🚀Race Condition (Staaten & Big Tech):
Dies ist meiner Meinung nach der wichtigste Treiber dafür, dass die bekannten Risiken schlichtweg ignoriert werden.
Wer bremst zuerst?
Kapital und Staaten pushen mit Compute, Talenten, Strom und Chips nach vorn.
Der AI Index zeigt Rekordinvestitionen, massive staatliche Programme und eine immer schnellere Skalierung am Frontier.
Hier eine paraphrasierte Passage aus dem Buch, die das Problem verdeutlicht:
Mehrere Unternehmen steigen wie auf einer Leiter im Dunkeln nach oben.
Jede Sprosse bringt enorme finanzielle Gewinne (10 Milliarden, 50 Milliarden, 250 Milliarden USD usw.). Doch niemand weiß, wo die Leiter endet – und wer die oberste Sprosse erreicht, lässt die Leiter explodieren und vernichtet alle.
Trotzdem will kein Unternehmen zurückbleiben, solange die nächste Sprosse scheinbar sicher ist.
Einige Führungskräfte glauben sogar, nur sie selbst könnten die „Explosion“ kontrollieren und in etwas Positives verwandeln – und fühlen sich deshalb verpflichtet, weiterzusteigen.
Dasselbe Dilemma gilt auch für Staaten: Kein Land will seine Wirtschaft durch strenge KI-Regulierung schwächen, während andere Länder ungebremst weiterforschen. Vielleicht, so denkt man, ist der nächste Schritt sogar nötig, um die nationale Sicherheit zu wahren.
Das Problem ließe sich leichter lösen, wenn die Wissenschaft genau bestimmen könnte, ab welcher Leistungsgrenze KI wirklich gefährlich wird. Etwa: „Die vierte Sprosse ist tödlich“ oder „Ab 257 000 GPUs droht Gefahr“. Doch eine solche klare Grenze gibt es nicht.
Eine potenzielle, echte „Tragedy of the Commons“. 🤷♂️
In der Theorie könnten LLMs beliebig „intelligent“ werden, solange sie genügend Parameter, Daten und Rechenleistung haben.
Das folgt aus der Church-Turing-These: Ein hinreichend großes neuronales Netz kann (mit genug Präzision) jede berechenbare Funktion approximieren, also auch eine beliebig „intelligente“.
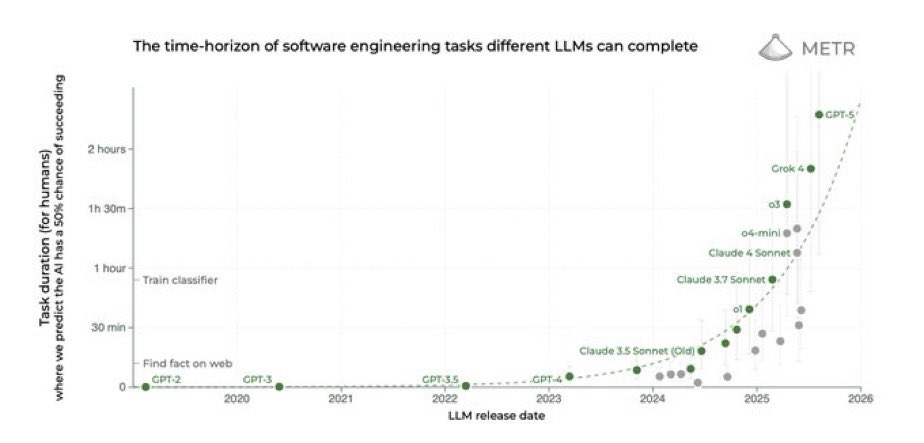
Die Fähigkeitsentwicklung, die wir gerade sehen, scheint einer exponentiellen Kurve zu folgen.
Wie viel Compute wir wirklich brauchen, um AGI zu erreichen, weiß niemand.
Es kann sein, dass wir in fünf Jahren an diesen Punkt kommen, in zehn, zwanzig oder dreißig Jahren.
__________________________
🔮Der kontroverseste Teil des Buches. Die Prognose:
Das Buch malt die Auslöschung der Menschheit in weniger als 20 Jahren als plausibel, wenn wir die AI-Entwicklung nicht stoppen.
Ob man die Zahl glaubt oder nicht, die Timelines vieler Forschender sind in den letzten Jahren deutlich nach vorn gerutscht.
Die AI Impacts Surveys (z. B. 2016, 2022, 2023) haben KI-Forscher weltweit befragt, insbesondere solche, die auf großen Fachkonferenzen wie NeurIPS, ICML oder AAAI veröffentlichen.
Die Surveys zeigen einen klaren Trend zu kürzeren AGI-Timelines und signifikante p-doom-Werte. (p-doom bezeichnet das Risiko einer Auslöschung der Menschheit durch künstliche Intelligenzen.)
⏱️AGI/HLMI-Zeitpunkt (50 %-Chance, dass AI alle Aufgaben besser und günstiger als Menschen erfüllt – „High-Level Machine Intelligence“):
- 2016: ~2061
- 2022: ~2059
- 2023 (veröff. 2024): 2047
Der Sprung 2022 → 2023 betrug −13 Jahre. 🫨
💣p(doom) – „extrem schlechte Outcomes“
- 2022: Median 5%, 48% der Befragten geben >10 % an.
- 2023-Survey: 38–51% geben >10 % für Szenarien „so schlimm wie Auslöschung“ an.
Nicht Konsens, aber weit weg von Null.
Wir sprechen hier von der Einschätzung, dass mit einer Wahrscheinlichkeit um die 10%, die Menschheit ausgelöscht wird. 🤯
__________________________
Nun. Hat die Menschheit nicht schon diverse asymmetrische Risiken überstanden?
Was ist z. B. mit Atomwaffen? 🤔
Atomwaffenrisiken sind iterativ.
Die Menschheit kann mehrfach knapp entkommen (wie 1962, 1983, 1995).
AGI hingegen ist einmalig:
Wenn ein System mit unkontrollierbarer Macht entsteht, gibt es kein Zurück und keine zweite Chance.
„You only get one shot at aligning superintelligence, and you can’t debug it afterwards.“
– Eliezer Yudkowsky
Damit ist der Erwartungswert katastrophal hoch, selbst wenn die Wahrscheinlichkeit „klein“ (~10% laut führenden AI-Wissenschaftlern) ist.
Nuklearwaffen können töten.
Eine übermenschliche KI kann entscheiden, was in der Zukunft existiert.
__________________________
Schlusswort 🔚
Keine Frage: KI wird unser Leben in kurzer Zeit tief verändern.
Der wirtschaftliche Wert, den ein Mensch beisteuert, hängt in vielen Jobs schon heute davon ab, wie gut er KI als Werkzeug nutzt.
Aber wie lange noch, bis fast alle Tätigkeiten ohne menschliches Fingerspitzengefühl oder Einfühlungsvermögen von KI erledigt werden?
Der Satz „Ich möchte von einem Menschen bedient werden“ ist für mich vor allem Qualitätsanspruch und Vertrauensfrage.
KI ist neu und oft noch nicht verlässlich genug.
Doch was, wenn sprechende KI-Avatare nicht mehr von Menschen zu unterscheiden sind?
Welches Unternehmen, welcher Staat kann es sich dann noch leisten, nicht Schritt für Schritt mehr Verantwortung an KI abzugeben?
Unabhängig davon, was man von Yudkowskys Prognosen hält:
Er mag dramatischer klingen als andere, trifft aber einen wunden Punkt.
Wir haben mit AI Pandoras Büchse geöffnet und bauen beim Thema „AI alignment“ erstaunlich viel auf Hoffnung.
Yudkowsky steht damit nicht allein; die Verschiebungen in den AI-Impacts-Umfragen zeigen eine klare Tendenz.
Und jetzt die obligatorische Frage an euch:
Wie beurteilt ihr die existentielle Gefahr durch AI? 😳